 I was searching for some information on using the Eclipse IvyDE plug-in and found a post that reminded me of some work I did last summer. For the most part, I’m happy with the way the IvyDE plug-in works, but sometimes you have to be a little tolerant of its usability issues. Every so often, IvyDE seems to forget about my configuration and refuses to add libraries to the class path. My only option is to remove Ivy Dependency Manager and re-add it to the class path. One problem that I’ve been unable to solve, is the integration of an Eclipse Web Tools Platform (WTP) project and Ivy; I cannot get the Ivy resolved libraries added into a “Dynamic Web Project”, making them available to the Tomcat. I have tried a dozen different configurations and settings with no success. Hopefully, I will get this working in the near future. If anyone has this working, please give me some tips!
I was searching for some information on using the Eclipse IvyDE plug-in and found a post that reminded me of some work I did last summer. For the most part, I’m happy with the way the IvyDE plug-in works, but sometimes you have to be a little tolerant of its usability issues. Every so often, IvyDE seems to forget about my configuration and refuses to add libraries to the class path. My only option is to remove Ivy Dependency Manager and re-add it to the class path. One problem that I’ve been unable to solve, is the integration of an Eclipse Web Tools Platform (WTP) project and Ivy; I cannot get the Ivy resolved libraries added into a “Dynamic Web Project”, making them available to the Tomcat. I have tried a dozen different configurations and settings with no success. Hopefully, I will get this working in the near future. If anyone has this working, please give me some tips!
The real thought behind this post was echoed in this post by Daniel Spiewak, So Long WTP, Embedded Jetty For Me. I was really fired up about Jetty last summer. When compared to my experience developing Weblogic-based applications, the utter simplicity and flexibility of Jetty was amazing. I was working on a custom Servlet-based web service framework and decided to do my development with Jetty. I created a very small Java program that configured Jetty to deploy my Servlet, in about 20 lines of code! The best part is there was no special Eclipse project type, no special environment, and zero deployment work; making debugging and testing especially easy. I never used the word embedded when I talked about Jetty, but that was exactly what I wanted. I always deployed in the Weblogic container because of our corporate standards. I should have explored this a little more, further highlighting the point that Weblogic and all of its complexity is truly unnecessary.
Following the BEA Bible, you end up with specific machines, specific file systems, specific networking, and hardwired clusters. Combine that with an environment that is highly controlled, it can take a dozen change control tickets and multiple days to bring up a new instance. Not exactly what I call agile or responsive. How cool is would it be to just drop a WAR file on a machine (any available machine), launch java to bring up a web server, add it to the load balancer and instantly expand your processing capacity? Pretty powerful idea, I think.
Embedding a web server is a good idea when building a web-based application, both for development and operational reasons. A good example is the Hudson Continuous Integration tool. Hudson is distributed as a single WAR file that you can pop in any Servlet container; but it also includes an embedded web server. This approach is becoming more and more common, as several open-source and commercial products are shipping their products with embedded web servers. The real benefit is flexibility. It literally took me seconds to get Hudson up and running; no messing around with Tomcat, no configuring security realms, no anything! It allowed me to focus on Hudson, rather than the environment to make it work. Down the road, if I want to deploy Hudson in the standard application server environment, it should be an easy switch, This is quite different from my recent experience installing a few open-source code review tools; installing multiple Python packages, configure an Apache web server, setting up database servers, etc. I don’t think I have to say much more; the better choice is pretty obvious.
 It is pretty hard to beat the Eclipse WTP – Apache Tomcat integration as a development environment, but directly embedding Jetty into your environment (no WTP) would make the environment even simpler. I have been trying to encourage teammates to develop from a container independent perspective, demonstrating higher productivity with no additional risk to the project. If we can move from large, monolithic applications to smaller, self contained services, the attractiveness of Jetty goes way up. The flexibility of running a moderately sized collection of small, independent services, verses a small tightly coupled clusters of monoliths, has to be an attractive architectural vision.
It is pretty hard to beat the Eclipse WTP – Apache Tomcat integration as a development environment, but directly embedding Jetty into your environment (no WTP) would make the environment even simpler. I have been trying to encourage teammates to develop from a container independent perspective, demonstrating higher productivity with no additional risk to the project. If we can move from large, monolithic applications to smaller, self contained services, the attractiveness of Jetty goes way up. The flexibility of running a moderately sized collection of small, independent services, verses a small tightly coupled clusters of monoliths, has to be an attractive architectural vision.
Unfortunately, many corporations don’t eagerly embrace open-source software solutions, preferring to pay for name recognition and guaranteed support. I personally feel that Jetty is a viable option, but it seems to be relatively unknown to most developers. Apache Tomcat and JBoss have a much higher exposure level, giving them more perceived viability. Jetty is no slouch, check out the Powered by Jetty page. Hopefully, this and Daniel’s post demonstrate there are alternatives to the J2EE Silver Bullet, and that we don’t really need to do everything by the J2EE book. There are a lot of simple alternatives out there for us to take advantage of, all we have to do is keep an open mind!

 While looking for the title to my post, I have found a little snippet that calling “Spring a direct attack on J2EE“. I thought this was a unique way of describing the Spring Framework. For sometime now, I have been on the bandwagon to simplify the development practice through Spring (Spring Core, Security and Remoting). I never really thought about Spring as another religious battle front; such as the classic emacs/vi or mac/pc wars. In essence, I was picking a side: No more J2EE! I guess it was not obvious to me before today, as I really can’t escape the J2EE container; I’m are required to deploy in a J2EE container, even though I make no use of its capabilities; a Servlet container is all most of us really need! Just an interesting thought! Agree or Not?
While looking for the title to my post, I have found a little snippet that calling “Spring a direct attack on J2EE“. I thought this was a unique way of describing the Spring Framework. For sometime now, I have been on the bandwagon to simplify the development practice through Spring (Spring Core, Security and Remoting). I never really thought about Spring as another religious battle front; such as the classic emacs/vi or mac/pc wars. In essence, I was picking a side: No more J2EE! I guess it was not obvious to me before today, as I really can’t escape the J2EE container; I’m are required to deploy in a J2EE container, even though I make no use of its capabilities; a Servlet container is all most of us really need! Just an interesting thought! Agree or Not? Factories are so 1990. This is one hurdle that some developers have a tough time understanding. They continue to think about creating objects via factories. There is NO need to ever create a factory when using Spring. Spring is essentially the a super factory, plus it is actually responsible for the life-cycle of those vended objects. There are scenarios where you need to specifically create objects that Spring manages, in a loop for example; but these are very uncommon. The proper way to solve this problem, is to create a bean that is ApplicationContextAware. When this bean is created (by Spring itself), Spring will set the application context on this bean. Now, you have the ability to ask for any bean that Spring is managing.
Factories are so 1990. This is one hurdle that some developers have a tough time understanding. They continue to think about creating objects via factories. There is NO need to ever create a factory when using Spring. Spring is essentially the a super factory, plus it is actually responsible for the life-cycle of those vended objects. There are scenarios where you need to specifically create objects that Spring manages, in a loop for example; but these are very uncommon. The proper way to solve this problem, is to create a bean that is ApplicationContextAware. When this bean is created (by Spring itself), Spring will set the application context on this bean. Now, you have the ability to ask for any bean that Spring is managing. This is probably the toughest habit to break and is easiest pattern to get stuck in. This is especially true if you are trying to integrate Spring into an existing project and is your first attempt at Inversion of Control. You will have a much better chance understanding these constructs, if you can start from a clean slate (or at least create a bunch of samples). Spring done right, is truly is a different way of thinking. For example, when working with a context-aware Servlet, you fundamentally NEVER need to ask Spring for a single instance; this is almost a perfect example of IOC and DI. The whole point of DI is the INJECTION. It is not about ASKING for an instance, it is about being GIVEN an instance; throw in the IOC principle and your bean will be invoked at the RIGHT time to provide the appropriate behavior.
This is probably the toughest habit to break and is easiest pattern to get stuck in. This is especially true if you are trying to integrate Spring into an existing project and is your first attempt at Inversion of Control. You will have a much better chance understanding these constructs, if you can start from a clean slate (or at least create a bunch of samples). Spring done right, is truly is a different way of thinking. For example, when working with a context-aware Servlet, you fundamentally NEVER need to ask Spring for a single instance; this is almost a perfect example of IOC and DI. The whole point of DI is the INJECTION. It is not about ASKING for an instance, it is about being GIVEN an instance; throw in the IOC principle and your bean will be invoked at the RIGHT time to provide the appropriate behavior. This was an unusual one for me. I recently observed a project that used Spring to created multiple static Singleton factories to vend out a variety of instances, each factory with it’s own Spring context file. Needless to say, this application was far from easy to understand. To my surprise, there was even a factory specifically implemented for creating the business domain objects. Why this was done is still a mystery to me and seems to violate the true spirit of Spring. Why would I ever want to call DomainFactory.getNewWidget() or DomainFactory.getNewGadget()? The configuration had the domain beans defined in a separate Spring context file and oddly, used static methods to initialize specific properties of these new bean instances. There was no way which enabled the XML configuration to be overridden, allowing for different implementations. Worse yet, you were tied to the initialization behavior of the factory methods! Depending on your definition of a domain object, I see very little reason domain object dependency injection.
This was an unusual one for me. I recently observed a project that used Spring to created multiple static Singleton factories to vend out a variety of instances, each factory with it’s own Spring context file. Needless to say, this application was far from easy to understand. To my surprise, there was even a factory specifically implemented for creating the business domain objects. Why this was done is still a mystery to me and seems to violate the true spirit of Spring. Why would I ever want to call DomainFactory.getNewWidget() or DomainFactory.getNewGadget()? The configuration had the domain beans defined in a separate Spring context file and oddly, used static methods to initialize specific properties of these new bean instances. There was no way which enabled the XML configuration to be overridden, allowing for different implementations. Worse yet, you were tied to the initialization behavior of the factory methods! Depending on your definition of a domain object, I see very little reason domain object dependency injection. This is an interesting use of Ant in a Spring-based application. The idea here is to generate the Spring configuration and properties file from an Ant task, to specifically configure the context files to each deployment environment. They values are essentially baked into the application and unchangeable. It is bad enough to substitute property file values, but some developers actually substitute bean name references. This might be a little hard to follow, but the Spring XML configuration would define two different implementations of the same basic function, each with its own name. When the application is built, the Ant tasks would substitute ref=”bean1” for some environments and ref=”bean2” for others; everywhere that implementation was referenced in the configuration files. Call me crazy, but I don’t think this what the Spring creators ever intended!
This is an interesting use of Ant in a Spring-based application. The idea here is to generate the Spring configuration and properties file from an Ant task, to specifically configure the context files to each deployment environment. They values are essentially baked into the application and unchangeable. It is bad enough to substitute property file values, but some developers actually substitute bean name references. This might be a little hard to follow, but the Spring XML configuration would define two different implementations of the same basic function, each with its own name. When the application is built, the Ant tasks would substitute ref=”bean1” for some environments and ref=”bean2” for others; everywhere that implementation was referenced in the configuration files. Call me crazy, but I don’t think this what the Spring creators ever intended!








 Ok, that is just about enough Hudson for this month, unless I get fired up about
Ok, that is just about enough Hudson for this month, unless I get fired up about 
 So, how do you deploy your application if Hudson is running on a different machine than your Tomcat instance? Fortunately, Hudson provides a plug-in to solve this problem, simply named the
So, how do you deploy your application if Hudson is running on a different machine than your Tomcat instance? Fortunately, Hudson provides a plug-in to solve this problem, simply named the 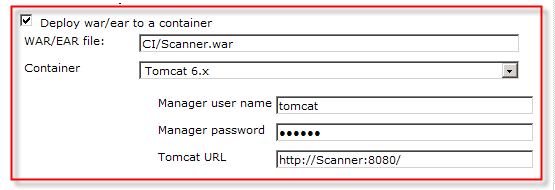
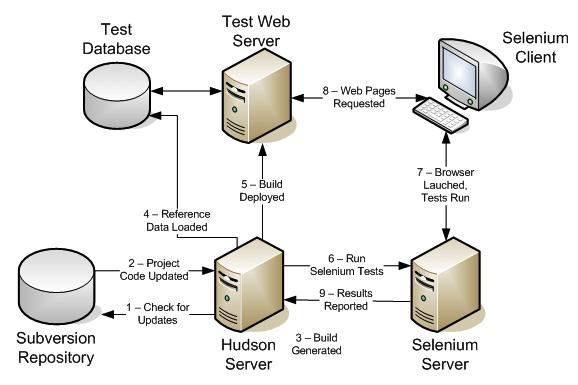



 One of the best things about the
One of the best things about the  My problem was, how to tie the Ivy dependency report into my continuous integration process. Building the report was easy, but how could I make it available on the main Hudson project page? Unfortunately, there was no plug-in to make this happen; I was actually thinking about writing my own plug-in this summer, but never quite got around to it (or blogging for that matter!) Fortunately, this appears to have been a common need and someone was nice enough to release a really nice plug-in this past July, called
My problem was, how to tie the Ivy dependency report into my continuous integration process. Building the report was easy, but how could I make it available on the main Hudson project page? Unfortunately, there was no plug-in to make this happen; I was actually thinking about writing my own plug-in this summer, but never quite got around to it (or blogging for that matter!) Fortunately, this appears to have been a common need and someone was nice enough to release a really nice plug-in this past July, called 
 I was looking for a development build of the IvyDE plug-in for Eclipse tonight and I stumbled across the
I was looking for a development build of the IvyDE plug-in for Eclipse tonight and I stumbled across the 

 I was working on a typical web portal application today and needed to support a multi-file download. Luckily, I had some code which I had used several times before. I started to tweak it for my specific requirements, realizing it was such a bad fit, I quickly tossed it out. My previous implementation worked with physical files and was tightly coupled to a legacy framework. This time, the files were already in memory. I was hoping to find some code that allowed me to build the zip file in memory, rather than dealing with the file system and temporary files. Since the portal user could only download a limited number of files at one time and the files were very small, I didn’t have to worry about memory constraints.
I was working on a typical web portal application today and needed to support a multi-file download. Luckily, I had some code which I had used several times before. I started to tweak it for my specific requirements, realizing it was such a bad fit, I quickly tossed it out. My previous implementation worked with physical files and was tightly coupled to a legacy framework. This time, the files were already in memory. I was hoping to find some code that allowed me to build the zip file in memory, rather than dealing with the file system and temporary files. Since the portal user could only download a limited number of files at one time and the files were very small, I didn’t have to worry about memory constraints. I have spent a lot of time discussing software principals and architecture over that last couple of years, and the subject of error handling and recovery always seems to always rear its ugly head. Most recently, in talking about moving from monolithic application deployments to a distributed, web service orientation, many developers seem to immediately go into paranoia mode. They only see two choices for working with distributed systems: the two phase commit or store everything approach, such that it can be resubmitted when the service is available. There is one other option which we cannot forget about, used by many applications regardless of their deployment, the traditional “logging, debug, retry” logic. Unfortunately, we developers like to add this code at the end of the development cycle, and usually as an after thought; but more on that later!
I have spent a lot of time discussing software principals and architecture over that last couple of years, and the subject of error handling and recovery always seems to always rear its ugly head. Most recently, in talking about moving from monolithic application deployments to a distributed, web service orientation, many developers seem to immediately go into paranoia mode. They only see two choices for working with distributed systems: the two phase commit or store everything approach, such that it can be resubmitted when the service is available. There is one other option which we cannot forget about, used by many applications regardless of their deployment, the traditional “logging, debug, retry” logic. Unfortunately, we developers like to add this code at the end of the development cycle, and usually as an after thought; but more on that later!
