
For whatever reason, I have been using a lot of Java Regular expressions at work lately; I started taking advantage of the grouping abilities provided by the standard Java Regular Expression implementation. I am certainly no RegEx expert, especial after reading this overview of backreferences and forward references! I use them every so often, probably not as much as I should; I know just enough to be dangerous! With my new exposure to grouping, I will probably use regular expressions much more frequently. Historically, if I needed to split a String into pieces, my goto class was the StringTokenizer. More often than not, I now use the String.split() method; you use create a simple regular expression and the method returns an array of the split values; It is actually easier to use and handles the case where no matches are discovered fairly well.
If you are going to create and use regular expressions, you are probably going to need to test them. I have been using web-based expression testers for several years; here is one that I use often; Tonight, I found a FireFox plug-in I like ever better!
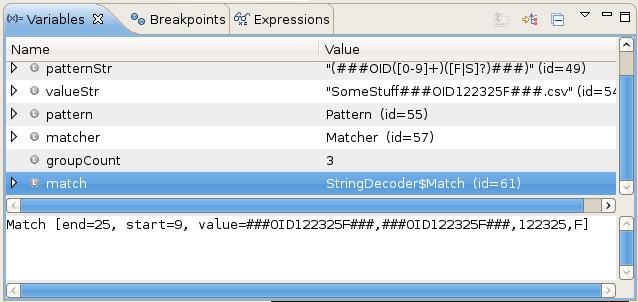
The point of this post was to show how easy it is to capture data using regular expressions. I created a little class to decode an id and status from a String. As illustrated in this simple example, you can use the Matcher class to do more than simply determine if the regular expression matched. With the addition of round brackets (parentheses) to the regular expression, we can actually capture the matched values in one simple step. This approach can also be used to capture optional values, the id and status, as in the included example. Unlike using a tokenizer or the split method, the Matcher class maintains the expected positions of non-specified, optional values; simply including an empty String for the optional attributes, when they are not provided. As you can see the following Eclipse debugger screen shot, the groups are easily accessible, even allowing you to build nested groups, as my example demonstrates. You can play with the example or give the Matcher JavaDoc a quick read to learn more about how this class works.
public class StringDecoder {
private static final Logger LOGGER = LoggerFactory.getLogger(StringDecoder.class);
private Collection<String> transactionIdentiferPatterns;
public class Result {
private long transactionId;
private String status;
private String filename;
public long getTransactionId() {
return transactionId;
}
public void setTransactionId(long transactionId) {
this.transactionId = transactionId;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public String getFilename() {
return filename;
}
public void setFilename(String filename) {
this.filename = filename;
}
}
private class Match {
private String[] group;
private int start;
private int end;
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append("Match [end=" + end + ", start=" + start + ", value=");
String comma = "";
for (String s : group) {
sb.append(comma).append(s);
comma = ",";
}
sb.append("]");
return sb.toString();
}
}
public void setTransactionIdentiferPatterns(final Collection<String> patterns) {
this.transactionIdentiferPatterns = patterns;
}
public Result decode(final String filename) {
Result rc = null;
for (final String pattern : transactionIdentiferPatterns) {
final Match match = find(StringUtils.trim(pattern), filename);
if (match == null) {
LOGGER.warn("No match found using pattern [{}]", pattern);
}
else {
LOGGER.info("Mache found {}", match);
rc = new Result();
rc.setTransactionId(Long.valueOf(match.group[2]));
rc.setStatus(match.group[3]);
rc.setFilename(filename.substring(0, match.start) + filename.substring(match.end));
return rc;
}
}
return null;
}
private Match find(final String patternStr, final String valueStr) {
final Pattern pattern = Pattern.compile(patternStr);
final Matcher matcher = pattern.matcher(valueStr);
if (matcher.find()) {
final int groupCount = matcher.groupCount();
final Match match = new Match();
match.group = new String[groupCount + 1];
for (int i = 0; i <= groupCount; i++) {
match.group[i] = matcher.group(i);
if (i == 0) {
match.start = matcher.start();
match.end = matcher.end();
}
}
LOGGER.debug("Good {}", match);
return match;
}
return null;
}
@Test
public void simple() {
Collection<String> patterns = new ArrayList<String>();
patterns.add("(###OID([0-9]+)([F|S]?)###)");
this.setTransactionIdentiferPatterns(patterns);
String name = "SomeStuff###OID122325F###.csv";
Result result = this.decode(name);
assertEquals(122325, result.getTransactionId());
assertEquals("SomeStuff.csv", result.getFilename());
assertEquals("F", result.getStatus());
}
}









 Ok, that is just about enough Hudson for this month, unless I get fired up about
Ok, that is just about enough Hudson for this month, unless I get fired up about 
 So, how do you deploy your application if Hudson is running on a different machine than your Tomcat instance? Fortunately, Hudson provides a plug-in to solve this problem, simply named the
So, how do you deploy your application if Hudson is running on a different machine than your Tomcat instance? Fortunately, Hudson provides a plug-in to solve this problem, simply named the 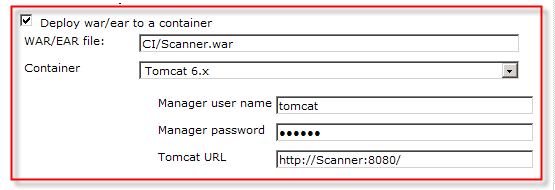
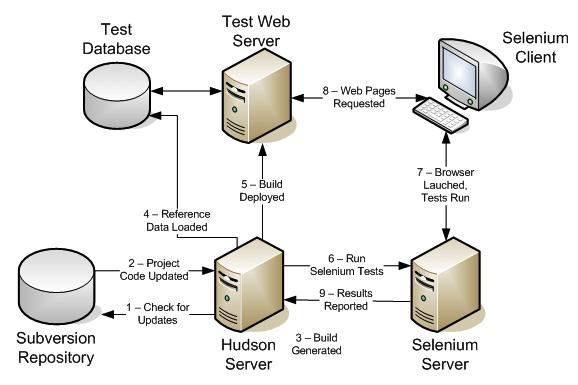
 I have been so busy with work and life, that my blogging had basically stopped for the summer. I keep sending myself topics and notes about things that I would like to write about. Unfortunately, I have not had a chance to do anything with them and the topics keep piling up! I was talking with one of my coworkers last month, and he mentioned that he also had a blog. I mailed myself the link to his site,
I have been so busy with work and life, that my blogging had basically stopped for the summer. I keep sending myself topics and notes about things that I would like to write about. Unfortunately, I have not had a chance to do anything with them and the topics keep piling up! I was talking with one of my coworkers last month, and he mentioned that he also had a blog. I mailed myself the link to his site, 


 One of the best things about the
One of the best things about the  My problem was, how to tie the Ivy dependency report into my continuous integration process. Building the report was easy, but how could I make it available on the main Hudson project page? Unfortunately, there was no plug-in to make this happen; I was actually thinking about writing my own plug-in this summer, but never quite got around to it (or blogging for that matter!) Fortunately, this appears to have been a common need and someone was nice enough to release a really nice plug-in this past July, called
My problem was, how to tie the Ivy dependency report into my continuous integration process. Building the report was easy, but how could I make it available on the main Hudson project page? Unfortunately, there was no plug-in to make this happen; I was actually thinking about writing my own plug-in this summer, but never quite got around to it (or blogging for that matter!) Fortunately, this appears to have been a common need and someone was nice enough to release a really nice plug-in this past July, called 

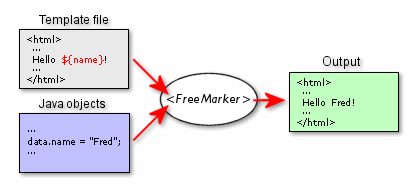 I liked the Freemarker overview picture, taken from the
I liked the Freemarker overview picture, taken from the