 I recently did an impromptu survey of some friends and coworkers concerning how they conduct code reviews. The responses I got back were a little surprising and definitely not what I was hoping for. None of the responses were incorrect or wrong, but I was hoping that my vision and theirs would be a little more aligned.
I recently did an impromptu survey of some friends and coworkers concerning how they conduct code reviews. The responses I got back were a little surprising and definitely not what I was hoping for. None of the responses were incorrect or wrong, but I was hoping that my vision and theirs would be a little more aligned.
Like many of you, I have been involved in my fair share of code reviews. Unfortunately, most of these quote code reviews are more of a code presentation, rather than an actual review. The presenters typically don’t prepare anything for the reviewers, and if they do, the reviewers never have the time to study or evaluate the material. Once the code has been reviewed, you have the challenge of dealing with the issues generated by the reviewers: How are the issues being tracked? Is there a discussion or evaluation of each issue? How are the issues being prioritized? When and how will each issue be fixed? Don’t forget about the general coordination and procedural aspects: Who is doing the coordination? What code is being reviewed? Who are the scribes? What is the appropriate tracking or reporting format? This is all part of the traditional code review process, or so I thought!
The most interesting response from my survey was that many people considered my definition of a code review to be rather old school and non productive. I’m not old school, just getting older and hopefully wiser! Several teams said they used tools like Checkstyle and PMD to verify the code, combined with Agile and Pair Programming techniques; thus minimizing (but not eliminating) the need for an actual code review. Teams that conducted reviews seemed to prefer the Net-Meeting (a shared desktop) approach, over meeting together in a conference room. Net-Meetings can be valuable, but I believe that most people are either surfing or reading emails and generally not paying attention during the meeting. Some teams even fix issues right there in the code review. Personally, I think this is very bad practice and not a good use of everyone’s time. Up to this point in the process, I’m pretty much on board with everyone’s process, but I think there is too much informality and and not enough traceability in the overall process. I don’t want to add more bureaucracy, I actually want to make the process more efficient and effective.
I believe in the “pair programming” principal, but consider “pair designing” much more valuable. Teams could minimally implement (and should) some type of virtual partners to get the benefits of pair programming. I like working on projects where some of the team members monitor all of the check-ins, basically performing continual code reviews throughout the development process. I realize code reviews can have other potential values, such as cross training, mentoring, and promoting consistency and reuse. However, I don’t believe this is the purpose of a code review; isn’t it really about identifying programming flaws? So the question is, what is the most effective way to find bugs?
Some code reviews focus too much on the fluff. Are the indentations and parenthesis in the right place? Are the classes, properties, and variables named appropriately? Is the code well structured? All important aspects, but really don’t need to be addressed in a code review process. All of these issues should have been identified during construction phase using freely available tools, integrated with the IDE and the Continuous Integration (CI) process. I have been using the Checkstyle and PMD for many years to accomplish this task. They can provide value when the team requires the violations to be fixed. I typically configure the Eclipse plug-ins and CI tool to fail if any violations are encountered. Additionally, the CI tool will continue to run, spamming the contributors until the issues are resolved. I have the same philosophy for failed jUnit tests too, I run a tight ship! When violations or jUnit failures are flagged as warnings, rather than errors, they typically get ignored by the developers and are never addressed. When used correctly, Checkstyle and PMD will encourage and enforce specific coding practices, acting as a virtual coding partner, identifying issues when they are created. Personally, I think these tools help me write better code; as the code evolves and begins to deviate from the original design, these tools usually pick up on the “band-aids” and allow me to fix/adjust the design before it is too late. I recently added two more tools to my quality validation toolkit, Findbugs and the Testability Explorer. There is some functional overlap in these tools, but I still like using all of them as a suite, as they each do their job a little differently. Findbugs is very interesting, it works from the compiled byte code, rather than the source code. Findbugs analyzes your code and its interaction with the other included libraries. It will detect problems such as unclosed resources, synchronization issues, and returning mutable collections. The Testability Explorer is my current favorite, but not as easy to understand as the other tools. I will write about it in another post.
Let’s say that we have we have these tools in place and our code is super clean. Unless projects implemented pair programming and are skipping the code review process, most schedule some type of review at the end of the coding cycle. I think most teams identify a random subset of code and schedule a series of meetings to conduct the reviews. I say random because the developers pick and choose what files are to be reviewed. How can we be sure that all of the important changes have been identified? This is where each team charts their own path. Some teams have a code “presentation” session with no pre-meeting preparation what so ever. Other teams email out a source file or URL list for each file to review. On the last code review that I helped coordinate, we sent out FishEye URLs for each file to the reviewers. This was pretty cool, because the URL represented the actual changes, not simply a link to the file. This allowed the reviewer to focus on the changes, rather than the entire file. This is point where I believe the whole processes breaks down, how do you report changes back to the developer and track the resolution? Usually issues and comments are sent back in email format, added to a spreadsheet, and checked into version control. One team actually generated PDF versions of their source code and mailed that out, the reviewers then added annotations to the PDF for their comments; kind of interesting. At our code review meetings, we tried to walk through the email comments and tried to address each one. This worked pretty well for those that actually prepared, but we still had lots of manual follow up work.
What I dislike most about this process is the management of these problems. Wouldn’t it be interesting if each issue had its own mini-workflow and was stored in some kind of relational database. Ideally, some kind of Eclipse plug-in to manage them, not necessarily linking the issue directly to the source code, but giving the developer quick access to the problem and approximate location within the file. The issues could easily be easily categorized by type and severity, and managed by the development team, and ultimately reported to management. There are numerous commercial tools (SmartBear, Atlassian) and even open source tools (CodeStriker, Rietveld, Review Board) which will automate much of the review process. These tools are actually very cool. It would be so efficient to review, debate, and resolve each issue in an on-line tool, looking at the actuals changes; just click on the line where the problem exists and create a new comment (start a workflow). The biggest problem with many of these open source tools is around deployment. Many corporations have rules and processes for bringing in open-source tools. Most of these tools have tons of required components, just to make them work in the environment. Its not like I can just log on to one of the UNIX servers and do a bunch of apt-gets to install the software. Review Board for example, requires: python-setuptools, memcached, libmemcache-dev, Djblets, Django-Evolution, Django, flup, and Python Imaging Library, plus integration with a database. Oh, guess what… it does not support Sybase or Oracle! Why can’t these guys just give me WAR file that I can drop into an Tomcat server or better yet, have it integrated with Jetty so I can just fire it up!
Even though I appear to be on my own code review island, I will keep monitoring this tools for one that can easily be integrated into the corporate environment. I just might have to build it myself!

 I can’t believe that I just outsourced myself! After my recent Ubuntu upgrade experience, I finally pulled the plug and signed up with bluehost.com. For the money, it is really not a bad deal; especially if you are crazy enough to have multiple domains. Now I just have to figure out the logistics of changing the name servers and track down where the email goes. Not too big a deal, I’m just not looking forward to explaining to my family, just where to find their email!
I can’t believe that I just outsourced myself! After my recent Ubuntu upgrade experience, I finally pulled the plug and signed up with bluehost.com. For the money, it is really not a bad deal; especially if you are crazy enough to have multiple domains. Now I just have to figure out the logistics of changing the name servers and track down where the email goes. Not too big a deal, I’m just not looking forward to explaining to my family, just where to find their email!








 My Ubuntu 64-bit 9.04 upgrade did not go very smoothly, it left my machine un-bootable. The upgrade downloaded all of the packages, but seemed unable to install anything. The detail window was full of the same message, something about a dpkg failure. I was really bumming, as the upgrade on my 32-bit laptop worked flawlessly. I hoped that I could recover my blog, but was not exactly sure how it would workout. I tried using chroot after booting from the CD, but the install messed up the file system so badly, nothing would run.
My Ubuntu 64-bit 9.04 upgrade did not go very smoothly, it left my machine un-bootable. The upgrade downloaded all of the packages, but seemed unable to install anything. The detail window was full of the same message, something about a dpkg failure. I was really bumming, as the upgrade on my 32-bit laptop worked flawlessly. I hoped that I could recover my blog, but was not exactly sure how it would workout. I tried using chroot after booting from the CD, but the install messed up the file system so badly, nothing would run. It was pretty easy to recover MySQL and WordPress. I never took the time to figure out how to backup MySQL, so I was a little worried about losing my blog data; I guess that will now be my number one priority. The restore was as simple as copying all of the files from /var/lib/mysql and /var/www from my old drive to the new drive. I just had to change the file owners and groups, restart MySQL, and my blog was back, up and running. Not too bad!
It was pretty easy to recover MySQL and WordPress. I never took the time to figure out how to backup MySQL, so I was a little worried about losing my blog data; I guess that will now be my number one priority. The restore was as simple as copying all of the files from /var/lib/mysql and /var/www from my old drive to the new drive. I just had to change the file owners and groups, restart MySQL, and my blog was back, up and running. Not too bad!



 We gave our youngest son a nitro RC truck, the
We gave our youngest son a nitro RC truck, the  A couple weeks ago, we took him down to the track to see a race. I was amazed at the money, this was definitely not a sport for kids! There were more than 50 people there and most of them there were pulling enclosed trailers behind their trucks. There was even a huge RV there, I have no idea where they drove in from! Each enclosed trailer was basically a mobile “pit area”; they all had generators, air compressors, little power washers, and every imaginable tool at their disposal. I thought I was at a NASCAR race, the kids thought it was pretty cool too.
A couple weeks ago, we took him down to the track to see a race. I was amazed at the money, this was definitely not a sport for kids! There were more than 50 people there and most of them there were pulling enclosed trailers behind their trucks. There was even a huge RV there, I have no idea where they drove in from! Each enclosed trailer was basically a mobile “pit area”; they all had generators, air compressors, little power washers, and every imaginable tool at their disposal. I thought I was at a NASCAR race, the kids thought it was pretty cool too.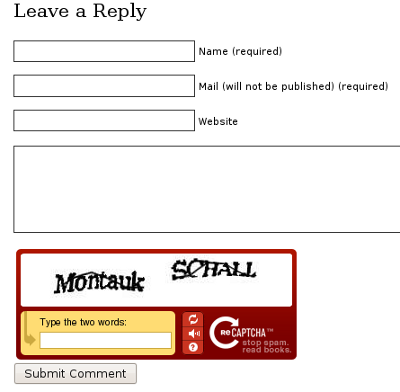 I was joking with my friends that President Obama had visited my blog twice last month and actually left some comments. I was so excited, but I could not understand why he was pushing Viagra…. those liberals are just too funny! My blog gets its fair share of spam, fortunately the Akismet plug-in does a really good job at flagging the spam comments; I just have to go into the dashboard every so often and clean them out.
I was joking with my friends that President Obama had visited my blog twice last month and actually left some comments. I was so excited, but I could not understand why he was pushing Viagra…. those liberals are just too funny! My blog gets its fair share of spam, fortunately the Akismet plug-in does a really good job at flagging the spam comments; I just have to go into the dashboard every so often and clean them out.